Legal Translation and Corpora: A Crash Course in Monolingual DIY Corpora for Legal Translators
Published on March 24, 2020 by Charles Eddy, legal translator in Lille

If you aren’t already using DIY corpora in your everyday legal translation practice, you should be: they can spark a sea change in how you work.
A resolutely data-driven approach, corpora improve the quality of your translations by helping you write in a more natural way that corresponds more closely to the norms of the target language and legal system.
As an added bonus, they can help unstick you when you’re in a tough spot and unable to choose the right word or phrase.
And when large traditional online corpora don’t do the trick, monolingual DIY corpora can be the perfect solution.
What are monolingual corpora?
A corpus (plural: corpora) is, put simply, a collected body of texts (the word is borrowed from the Latin for body).
Using a search interface, you can search through the corpus to find out how a given word is used in context.
Many translators are familiar with ordinary academic or institutional corpora such as the Corpus of Contemporary American English (COCA) or the British National Corpus (BNC), and it’s true—they can be used to great effect.
In fact, KWIC/concordance and collocate searches in these large corpora are already a part of many translators’ toolkits, and if they aren’t part of yours (especially if you’re a native translator into English, where corpus availability is vast), they should be.
What can a legal translator actually do with a monolingual corpus?
While the possibilities are vast, some are of greater interest to translators than others.
For instance, if you’re not sure that you’re using a word correctly, seeing it in context dozens of times can let you know whether you’ve got a handle on how other authors use it in real-world situations. This is sometimes called a “concordance” search or “KWIC” (KeyWord In Context) search.
You can also search for “collocates”—that is, which words naturally occur together. So if you want to know which words generally appear to the right of military, you can look that up (e.g. in a large U.S. corpus, the top words are: 1. Action; 2. Service; 3. Force; 4. Personnel; etc.). This helps you avoid translationese, letting you know with relative certainty whether two words generally go together or whether you might be using a word in a way native speakers do not.
Collocate searches also allow you to pin down the right word when you’re stuck. Ever say to yourself: “I know there’s a word that comes next to institutional, but I can’t think of which one…”? A collocate search can be a quick way of getting just that answer.
Lastly—although I’m just scratching the surface and there are many more things you can do—you can also use monolingual corpora like you would one half of translation memory. Want to see how severability clauses are written? If you have a contract corpus, just type in severability and you can pull up all the example clauses in your corpus.
And DIY corpora?
It’s all in the name. Do-it-yourself corpora are ad hoc text databases that you, the translator, build for a specific project, subject matter, etc.
Personally, I discovered them thanks to an article by Rudy Loock (@RudyLoock on Twitter), and it’s safe to say that they have, without a shadow of a doubt, helped me achieve better translation quality—which should be the focus for any translator looking to move upmarket and stay there.
DIY corpora can be as large or as small as you like, but keep in mind that you will be using your PC/Mac’s computing power and not a giant server located somewhere in the ether. The larger the corpus, the more horsepower it takes to search through it quickly, so if you don’t have a fast machine, it will be especially important to keep the size of the corpus you’re searching reasonable.
The great and wonderful thing about DIY corpora is that your corpus only has texts written by authors you choose in the field you choose, and—assuming you only select texts originally written in your target language—it will be entirely devoid of translationese. This means you won’t get calques or unfortunate phrasings that a native wouldn’t have used, which is important if you want your text to be as natural as possible in the target language
Building your first DIY translation corpus in under an hour
Time is often in short supply, so my goal here is to show you how you can get a basic corpus up and running in just minutes.
First, you’ll need to download software to search through the corpus you’re going to create.
Laurence Anthony’s AntConc software is the perfect way to get started.
- Download AntConc: http://www.laurenceanthony.net/software/antconc/.
While we’re at it, let’s grab his nifty AntFileConverter tool, which will let you transform DOCX and PDF files into usable corpus files.
- Download AntFileConverter: http://www.laurenceanthony.net/software/antfileconverter/.
Be sure to download the 64-bit versions if you have a 64-bit processor (which is the case for most computers manufactured in the last decade).
Now create a folder on your hard drive for your first corpus and start collecting text.
Your corpus can be on any topic you like, from a general “contract” corpus to very specific subject areas such as U.S. Supreme Court judgments related to tortious interference.
The choice is yours and the sky’s the limit.
Here, I’ll use the general example of Articles of Association.
Start by typing a query into your favorite search engine.
Here’s an example:
- lloyds bank plc “articles of association”
When you find a page that corresponds to what you’re looking for, there are two possibilities:
Microsoft Word (DOCX) or PDF files with searchable text
If you find a suitable DOCX or PDF file, download it and put it into the folder you created for this corpus. I suggest renaming the file to something easily recognizable.
Open AntFileConverter, drag and drop your files into the left column, and hit start.

The software will automatically put them into a subfolder called “txt” as properly encoded, ready-to-use text files.
Note that in most search engines (including Google), you can directly search for filetypes, as in these two example queries:
- lloyds bank plc “articles of association” filetype:pdf
- “articles of association” filetype:docx
Ordinary text on web pages
If what you’re looking for isn’t in a PDF or DOCX file, you can also go directly to a web page, copy and paste the text you want into Notepad, and save it as a .txt file in your corpus folder.
The only very important thing to remember when doing so is to select UTF-8 character encoding from the drop-down menu in Notepad when saving your text file (it’s a very visible option, so this isn’t complicated).
Keep repeating this process as needed, saving and converting additional documents, and you’ll soon end up with a collection of text files.
Your corpus is ready to use without any further manipulation.
Note: This process doesn’t necessarily have to be much more complicated than your current project workflow, and you are free to not take time to separately make a project-specific corpus. If your project already requires downloading PDFs and searching through them manually, why not save them to a folder and convert them with AntFileConverter? Then you can search through ALL the PDFs you’ve downloaded for your project, all at once, rather than looking through them individually.
An aside: A Source for English-language (specifically American) commercial contracts
If you’re looking to quickly build a contract corpus, try using your favorite search engine to search the SEC’s EDGAR database.
The easiest way is to use the “site” parameter. For instance, try putting the following words in your favorite search engine:
- manufacturing agreement site:sec.gov
On Google, this search returns a whopping 305,000 results!
Searching through your DIY corpus
Once you’ve built up your corpus by amassing a collection of texts, the search interface is where the magic happens.
Open AntConc and you’ll see this:
Click on File > Open Dir… (or Ctrl+D) and select the directory in which you placed your corpus files. Any text file in the directory (and its subdirectories) will automatically open and will appear on the left-hand side.
By default, you start in the Concordance tab. Type a word (or multiple words) and AntConc will display a list, in context, of each occurrence in your DIY corpus.

Now, click on any occurrence of the word in the results window and it will switch you over to the “File view” tab, where you will see your search term in more context, within the text itself. You can also peruse the contents of the file itself like you would any ordinary text file.
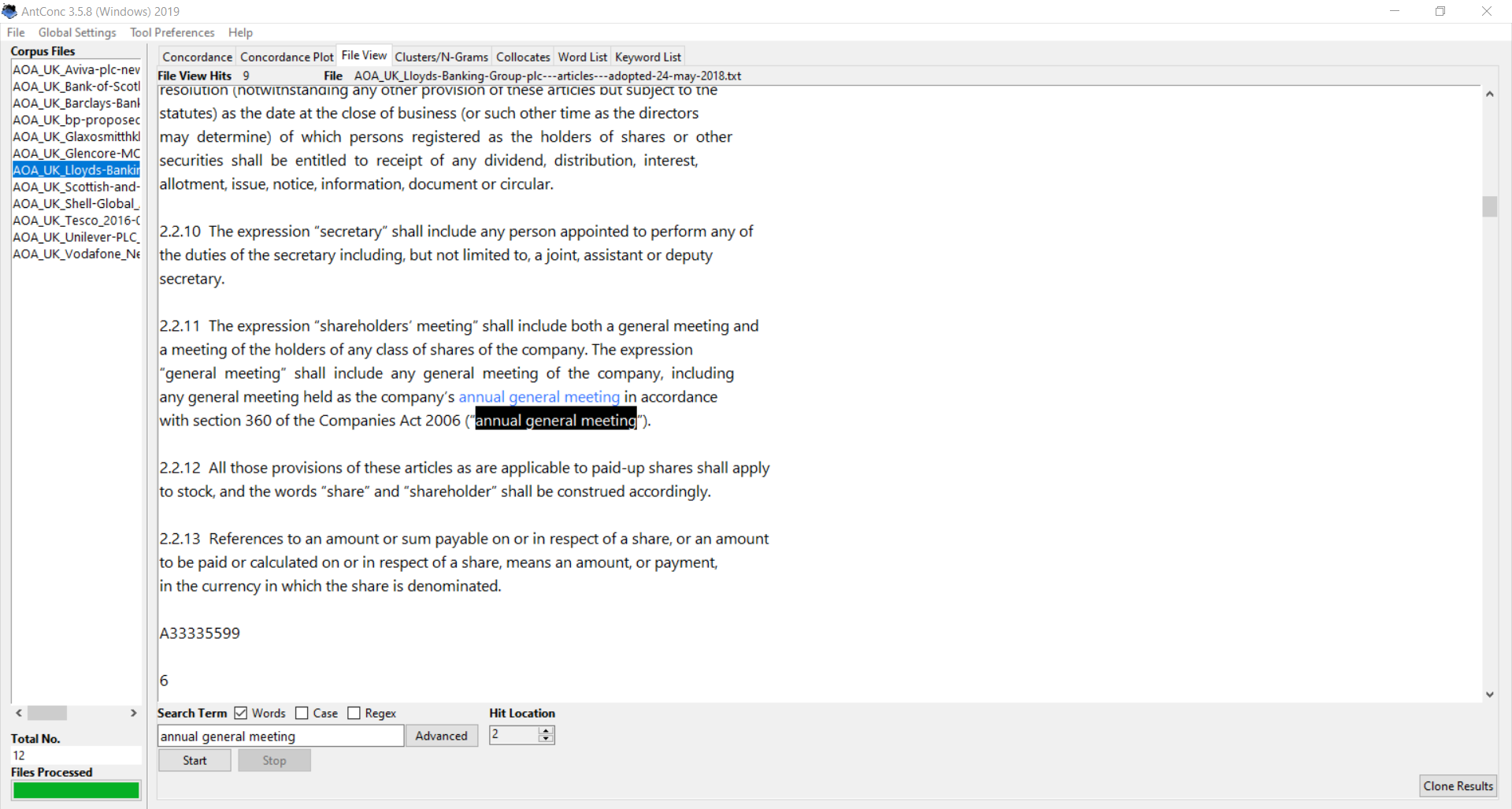
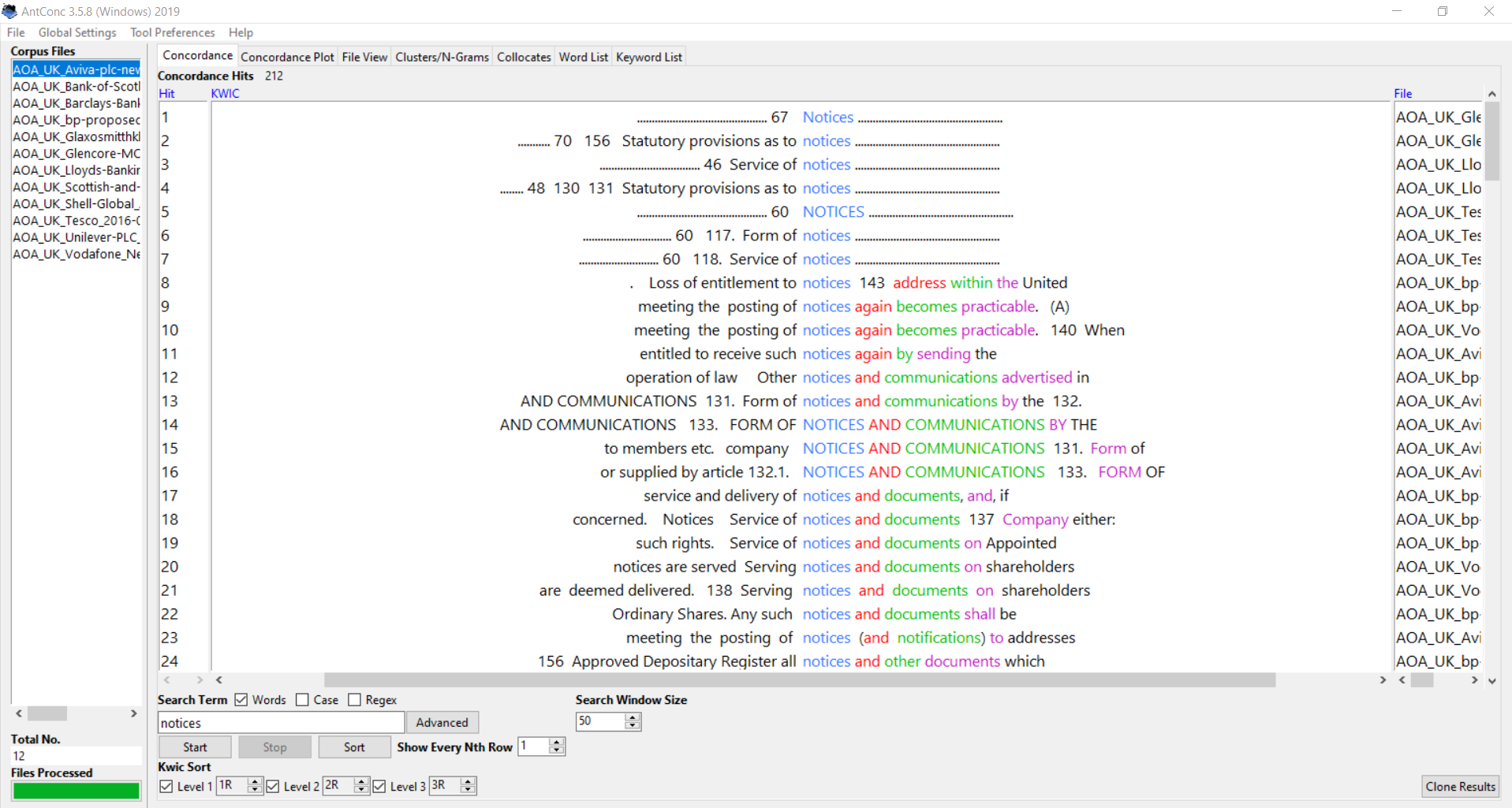
As I hinted at above, you might also find it useful to search for common section or clause names. Run a concordance search for an AoA section name like “Notices”, and the results will point you to that section. All that’s left is to click on the section header in the results to see a real-world example.
You can also use the asterisk (*) wildcard to search for multiple variants of a word. For example, if you want to see all variants of “renew” (renew, renewal, renewing, renewed), just type “renew*”.

Another useful feature I mentioned is collocate searching. Just head over to the collocates tab to begin. There are a couple options to look at first.
On the right you’ll see “From 5L to 5R” by default. This is shorthand for 5 words to the left and 5 words to the right of your search term. If you only want to see words very close to the search term, you can lower this number (I often use 2L and 2R).
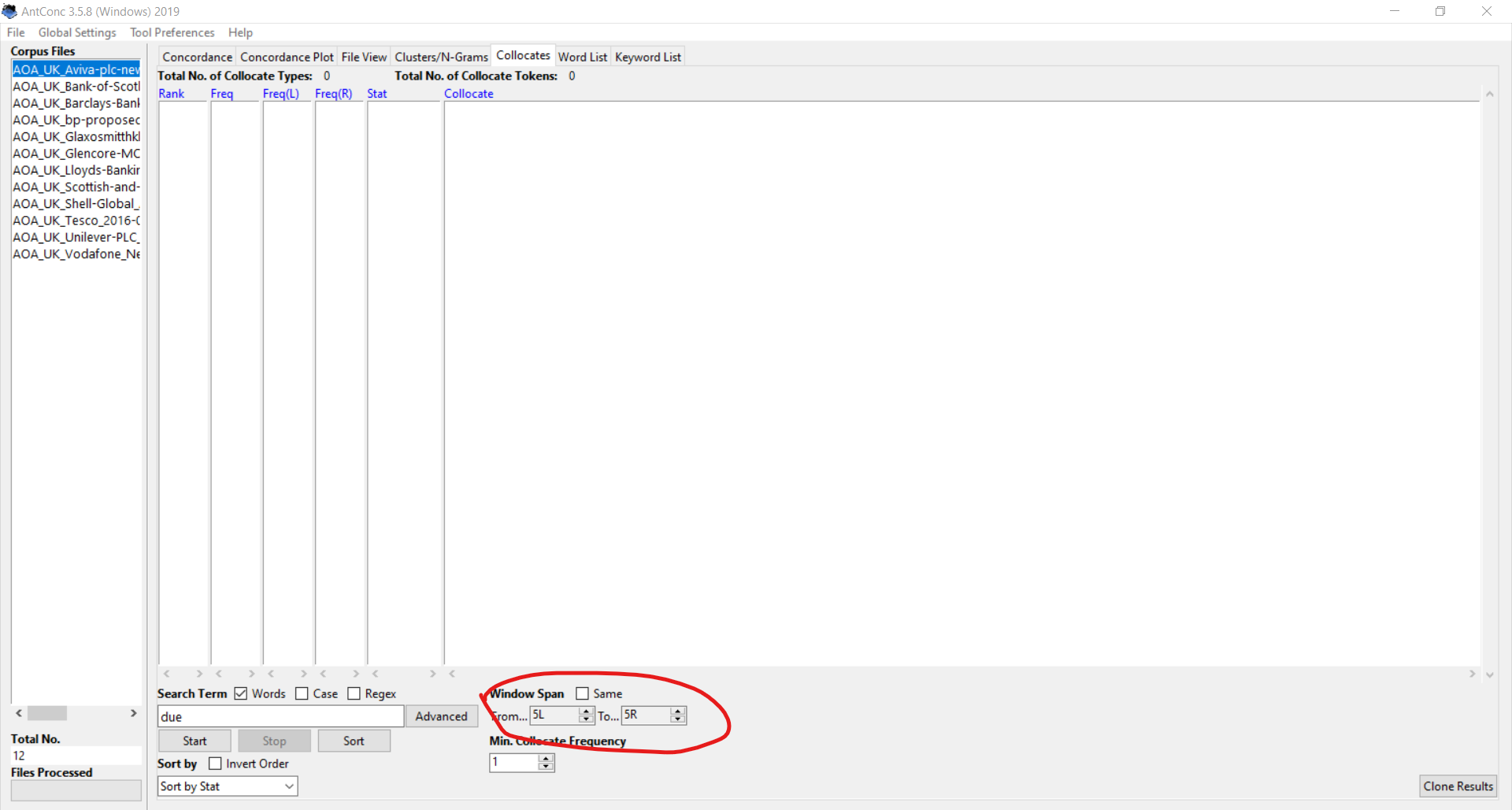
You can then click on the dropdown box at the bottom (set to “Sort by stat” by default) and select “Sort by freq(L)” (left) or “Sort by freq(R)” (right).
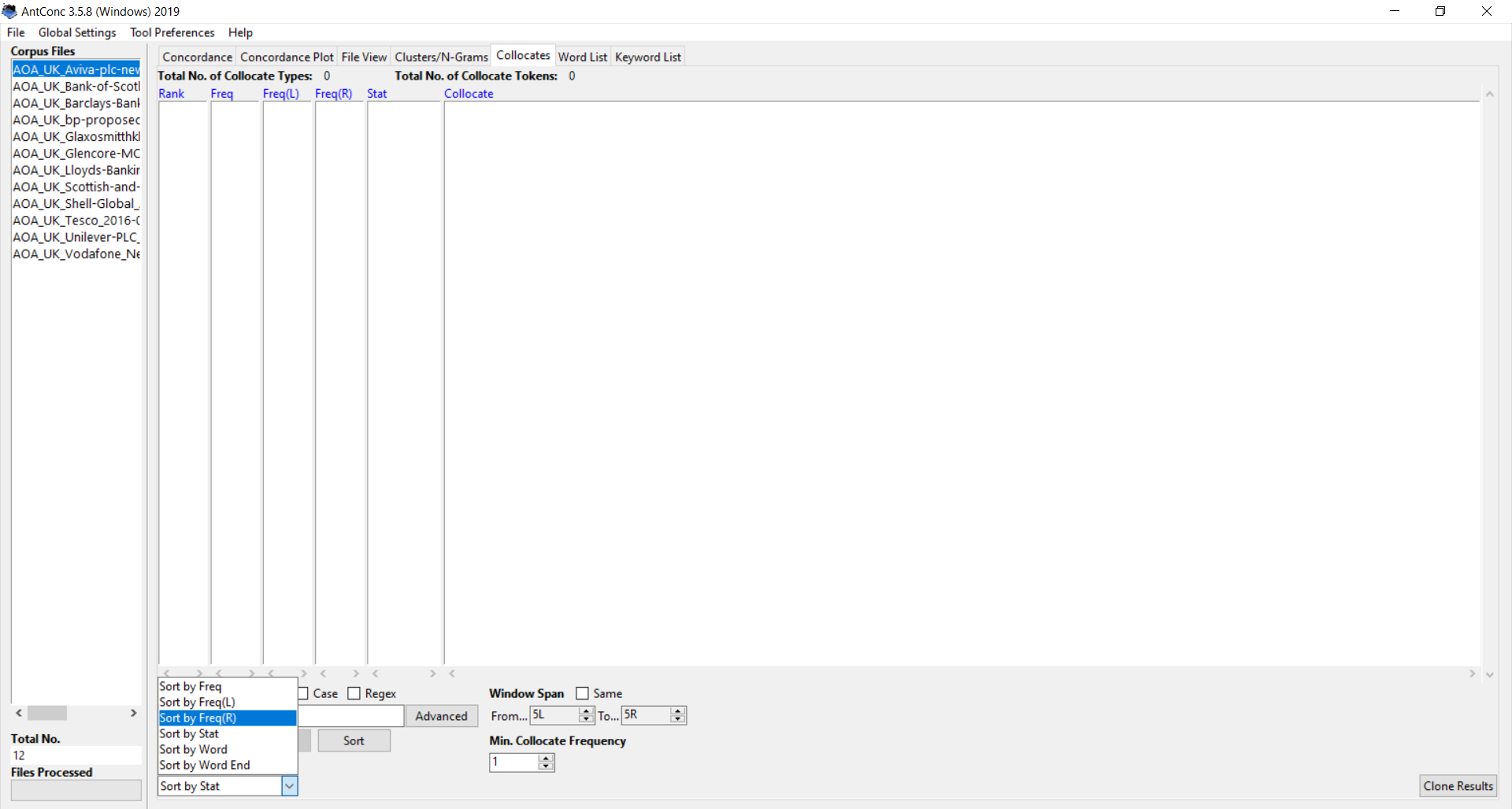
When you type in a word and run the search with one of these options, AntConc will show you the most common words occurring just to the left or just to the right of your search term. In the “freq(L)” and “freq(R)” columns, you can see how often the two terms occur together in your corpus.
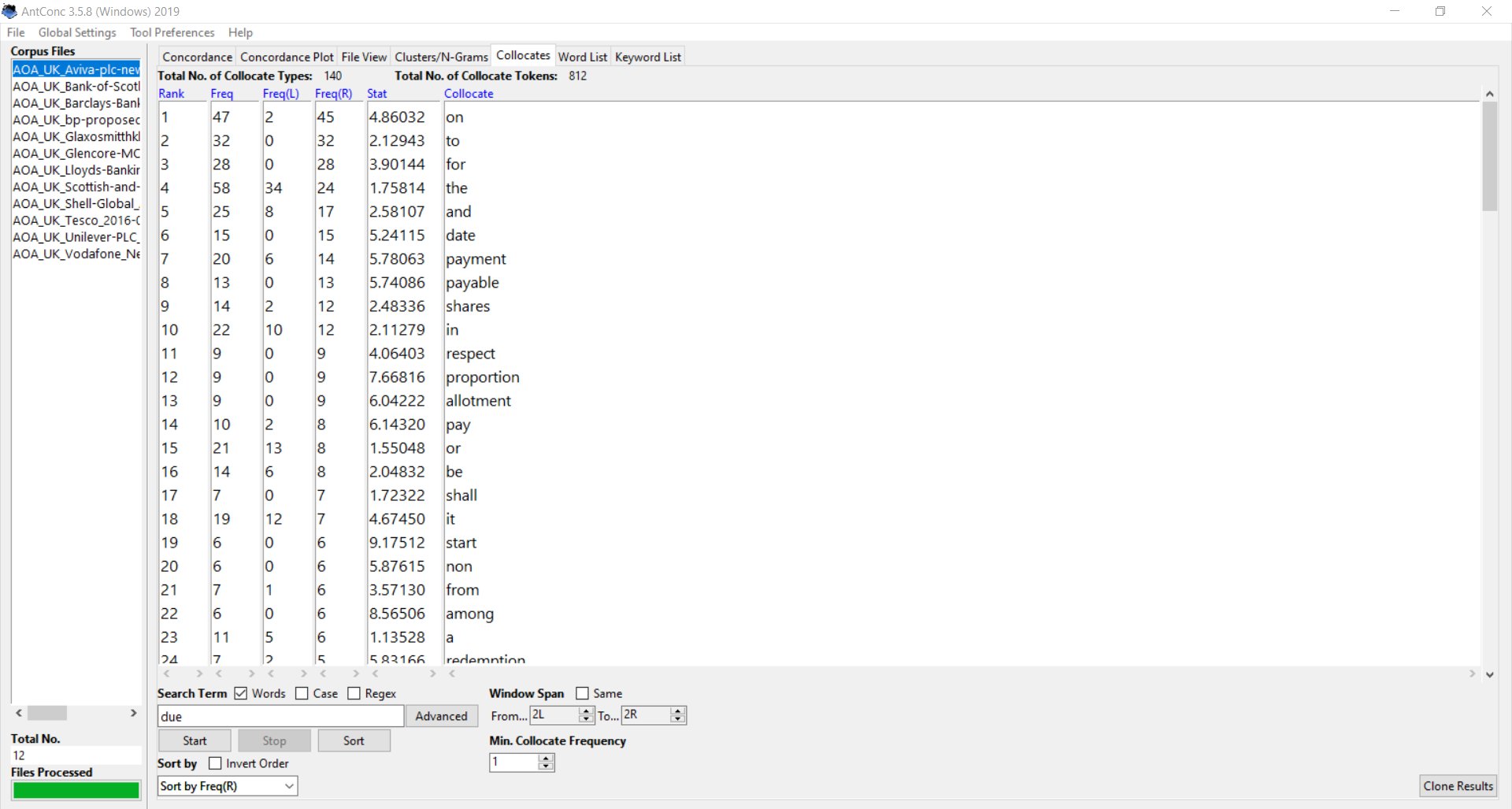
Click on any of the results in this list and you’ll jump to the concordance (KWIC) view, showing you these collocates in their actual context.

Similarly, if you want to see common clusters of words, use the Clusters/N-Grams tab. Adjust the cluster size to suit your needs (I generally use 2 as a minimum and 3 as a maximum), choose whether you want to look for your search term on the left- or right-hand side of the cluster, and click Start.

One last note: to see the size of your corpus (measured in word tokens, which for our purposes we’ll call words), use the word list tab:
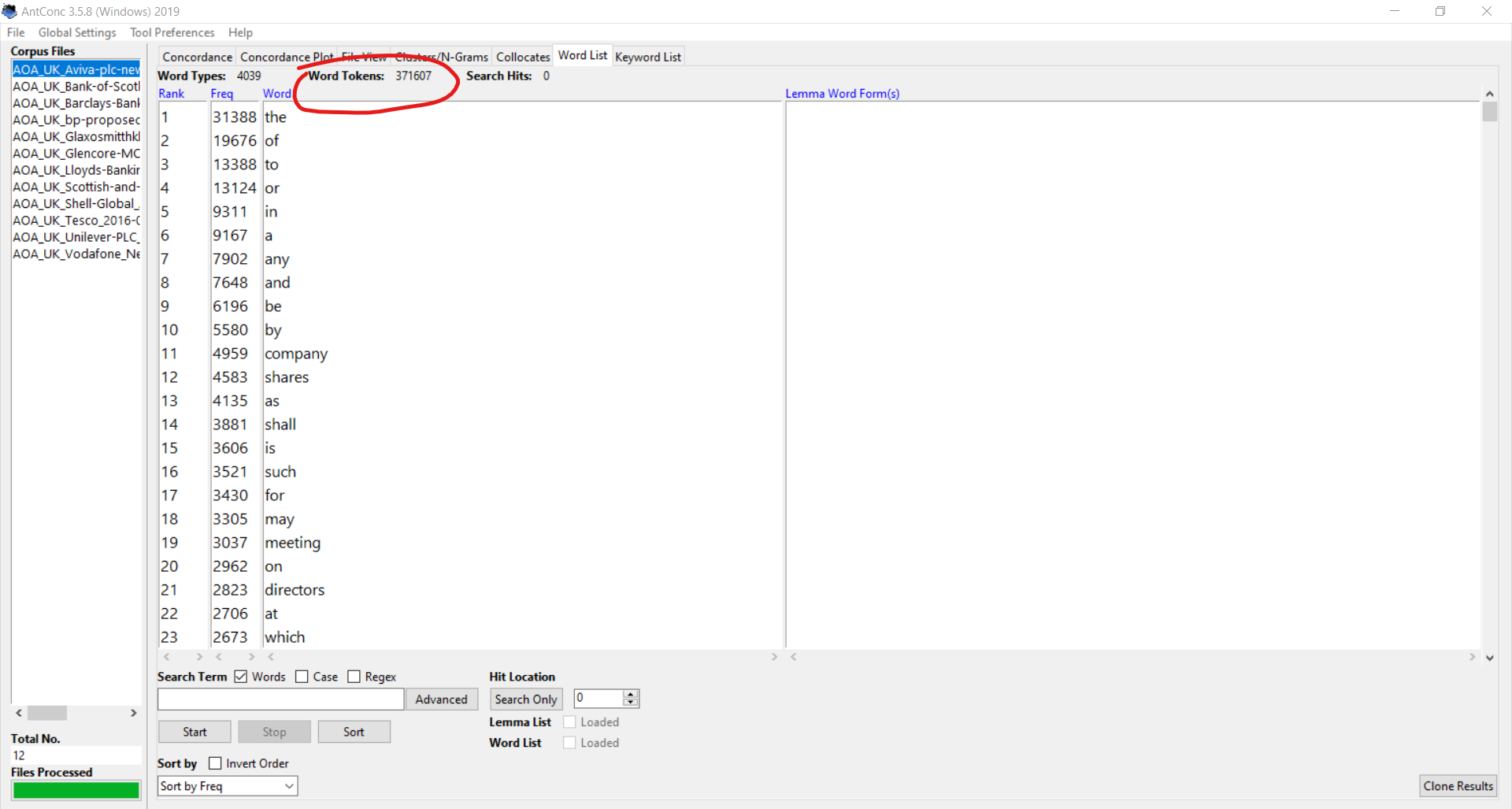
This number tells you the relative density of your corpus. You can choose to add files to get better results or remove files if your corpus gets too large to be manageable in terms of search query time. A few hundred thousand words will probably run quickly enough on a modern quad-core processor, but once you reach seven digit territory, waiting for your corpus to return results might feel a bit long-drawn.
This is, of course, not all you can do with your corpus, but these basic searches are already enough to get you up and running with AntConc.
Bonus: A mini-corpus to get you started
Eager to get started right away and test the power of DIY corpora?
You’re in luck.
I’ve downloaded and prepared a large (~5.4m word) version of the Delaware Code in plaintext (UTF-8) format, ready to be used in AntConc or your favorite concordancer.
To download it, click here: https://ceddytraductions.fr/docs/downloads/EN_Law_Delaware-Code.zip
As a disclaimer, this content is in the public domain. I provide no express or implied warranty whatsoever. Please be aware that this content is not up to date (I downloaded and prepared it in late 2018). As such, it should only be used as a corpus and not specifically for legal research purposes. If you need to access an up-to-date version of the Delaware Code, click here, and when in doubt, contact a lawyer for legal advice.
Also, I did mention this corpus is quite large, so don’t hesitate to open only a few files at a time to shorten the time needed to run a search.
Download this article in PDF format
If you want to keep this article around for reference, you can download it as a PDF here.
Thanks for reading!
I’d love to hear your thoughts on the article! Just leave a comment or discuss the topic with me on Twitter (@ceddytrad) or LinkedIn.
And be sure to share the article with friends and colleagues who might be interested!
In the market for legal translation services?
Looking for a French-English legal translation specialist to translate your legal documents? Look no further. Contact me today for a free quote.

